Importing Data Made Easy
Importing data is a problem that feels like it should have a library of work ready for you to use. Especially when it comes to importing data into Core Data where you have a description of your data to work with. What if there was such a library, or reusable framework, of importing code that basically converts raw data to Core Data entities? Well, wonder no further because in this post, I’ll be discussing a new addition to the MagicalRecord toolset, MagicalImport available now on Github!
Importing data is a simple idea, but one with many subtle complexities at the same time. The idea is easy: you need data in one form, typically an NSDictionary from a processed JSON string or file, to be converted to another form, the structured goodness of Entities in your Core Data model. This sounds a little like Object-Relational Mapping in the sense that you will need to tell MagicalImporting how data should be imported into your persistence mechanism. However, this case is slightly different as we’ll piggyback on Xcode, Core Data and the built in toolset to achieve our goals.
Goals
The data importing features now included in MagicalRecord were designed with a few design goals in mind:
- Be highly reusable
- Promote maintainable import code
- Don’t worry about performance until it’s a measured problem
- Solve the 90% case, but make most common exceptions easy to work around
- Keep all configurations out of code
It’ll be up to all of you to determine if I did indeed meet these goals, so I encourage you to grab a copy and try it out for yourself.
Implementation
Rather simply, we know what a Core Data entity looks like at a class-like level. I say class-like because NSManagedObject is a class itself, but it also describes how to store data, which is also a descriptive mechanism. An NSMangedObject has three key parts, the Entity Description, a list of attributes and a list of relationships. To import data, we first import all the attributes. This is a simple enumeration, and this step simply copies values from one object to the Managed Object.
The next step is to import relationships. This can be a bit more tricky depending on whether the relationship is a one-to-one or one-to-many relationship. Once you figure out that you need to import a new object, you start importing that as well. Start with importing attributes on the related objects, then start importing the relationships. Sound familiar? This sounds like a job for recursion!
Now, since you define reciprocal relationships in your Core Data models (if you don’t, you should), you will also have to be wary of traversing the relationship back to your original object and starting the import process all over again. This scenario is avoided if the data does not contain any cycles. Just like in physical memory, you could have a linked list of data, with the end of the list pointing back to the top of the list. Despite having a data model that is a fully connected graph, if your data doesn’t have cycles, you will avoid infinite recursion.
Oddly, during the import process, we can treat many-to-many as a one-to-many relationship since Core Data handles the many-to-many mapping for us. From the perspective of importing, we only work on one instance at a time, so at any point in time, looking out from an object through the many-to-many relationship, it will appear as if that single object is all that is involved.
The guiding philosophy during the development of MagicalImport was to assume that the defined Core Data model file is how the import data should be structured. That is, data you’re importing looks exactly like your data model. That makes the common importing code easy to write. And if that was all it did, MagicalImport would be less impressive. However, in real life situations, the source data never matches the data model exactly, but it does have generally minor deviations. By adding simple ways to handle these deviations, MagicalImport provides a simple, but powerful, framework for importing data into your Core Data based apps.
Features
Getting started with the MagicalImport is as easy as telling it where you want to start. The basic idea is you know which entity into which the data should be imported, so you then write a single line of code tying this entity with the data to import. There are a couple of options to kick off the import process. The first is by creating your own empty entity object, and telling that instance to import the data provided.
NSDictionary *contactInfo = //processed JSON data
Person *person = [Person MR_createEntity];
[person MR_importValuesForKeysWithObject:contactInfo];
This can be helpful if you’re basically overwriting data since MR_importFromObject: will also perform a lookup for an existing object based on a configured lookup value (described below). Also notice how this follows the built in paradigm of importing a list of key-value pairs in Cocoa, as well as following the safe way to import data.
For importing data, and automatically creating a new instance, starting with an entity class, and using a class method can also describe the process, in code, of importing a completely new set of data. Let’s see an example:
NSDictionary *contactInfo = /// result from JSON parser
Person *importedPerson = [Person MR_importFromObject:contactInfo];
The MR_importFromObject: method provides a wrapper around creating a new object using the previously mentioned MR_importValuesForKeysWithObject: method, and returns the newly created object filled with data.
A key item of note is that both these methods are synchronous. While some imports will take longer than others, it’s still highly advisable to perform all imports in the background so as to not impact user interaction. As previously discussed, MagicalRecord provides a handy API to make using background threads more manageable:
[MagicalRecord saveInBackgroundWithBlock:^(NSManagedObjectContext *)localContext {
Person *importedPerson = [Person MR_importFromObject:personRecord inContext:localContext];
}];
Array Import Wrapper
It’s common for a list of data to be served using a JSON array, or you’re importing a large list of a single type of data. The details of importing such a list are taken care of in the MR_importFromArray: method.
NSArray *arrayOfPeopleData = /// result from JSON parser
NSArray *people = [Person MR_importFromArray:arrayOfPeopleData];
This method, like MR_importFromObject: is also synchronous, so for background importing, use the previously mentioned helper method for performing blocks in the background.
If your import data exactly matches your Core Data model, then read no further because the aforementioned methods are all you need to import your data into your Core Data store. However, if your data, like most, has little quirks and minor deviations, then read on, as we’ll walk through some of the features of MagicalImport that will help you handle several commonly encountered deviations.
Codeless Data Mapping
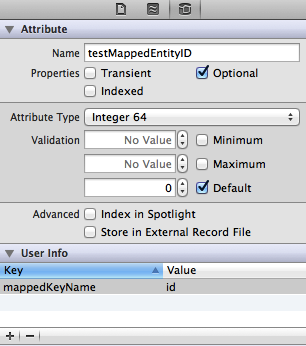 MagicalImport makes extensive use of the userInfo dictionary to make configuring various options available without editing code. The userInfo dictionary is simply an NSDictionary that is attached to each entity, attribute or relationship. The Xcode Model editor handily gives you access to this dictionary with a small three row view labeled ‘User Info‘. Each of the three key objects we deal with in Core Data, Entities, Attributes and Relationships, have specific MagicalImport options that are to be specified in the userInfo structure. This is important in providing context to MagicalImport. Since each Core Data object (entity, attribute and relationship) has it’s own set of mapping options, it’ll be easier to see at a glance that an attribute is using an option for an entity, for example.
MagicalImport makes extensive use of the userInfo dictionary to make configuring various options available without editing code. The userInfo dictionary is simply an NSDictionary that is attached to each entity, attribute or relationship. The Xcode Model editor handily gives you access to this dictionary with a small three row view labeled ‘User Info‘. Each of the three key objects we deal with in Core Data, Entities, Attributes and Relationships, have specific MagicalImport options that are to be specified in the userInfo structure. This is important in providing context to MagicalImport. Since each Core Data object (entity, attribute and relationship) has it’s own set of mapping options, it’ll be easier to see at a glance that an attribute is using an option for an entity, for example.
The guiding philosophy of assuming the data model and the imported data match exactly comes in handy when it comes to the mapping step. First, MagicalImport will assume that the names of the attributes and relationships of each entity are identical to the keys of the imported data. For example, if an attribute on an entity is called ‘name‘, MagicalImport will assume the key in the import data that matches that attribute is also called ‘name‘.
However, it’s rarely the case that source data matches your model exactly. So, to tell MagicalImport what key to look for, enter ‘mappedKeyName‘ as a key in the userInfo section of the specific attribute. The value of mappedKeyName is the key that MagicalImport will use in order to query your object for a value. It’s a level of indirection that can be a little confusing, however, since it’s tied directly to the attribute to which the data is tied, it should be a little more clear that this is the mapping from the source data to your Core Data model.
Relationships also use the mappedKeyName option to specify which value in the source data maps to the relationship. Relationship key mapping works exactly as attribute key mapping, which will be important regarding more of the features of MagicalImport.
In the case of missing data, such as an attribute that is not present in the imported data, MagicalImport will simply not import anything into that attribute.
Data Keypath Support
Key Value Coding is a common and effective tool in Objective C. MagicalImport gives you access to some of this power by allowing you to specify keyPaths as part of a mappedKeyName. If you’re familiar with KVC, this should be a fairly straightforward feature as Magicalmport passed these specified keys to the KVC methods under the covers.
Keypath support allows you to map data to an entity that may not have exactly the same hierarchy as the data model. For example, a data entity may store latitude and longitude, but the source data looks more like this:
{
"name": "Point Of Origin",
"location":
{
"latitude": 0.00,
"longitude": 0.00
}
}
In this case, we can specify as our data import key paths, location.latitude and location.longitude in our mappedKeyName configuration to dig into the nested data structure and import those values specifically into our core data entity.
Related By Keys
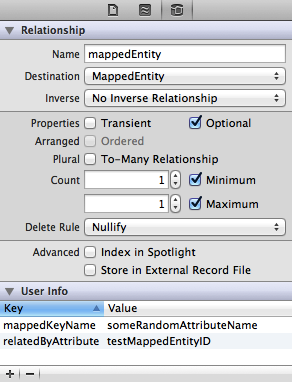 In classic relational databases, there exists the concept of a primary key. This has several nasty implications which I won’t get into here. However, for data importing to be automatic, it’s necessary to borrow this concept.
In classic relational databases, there exists the concept of a primary key. This has several nasty implications which I won’t get into here. However, for data importing to be automatic, it’s necessary to borrow this concept.
In order for automatic object to object mapping to occur, MagicalRecord needs to have a concept familiar to most database developers, that of a primary key.
MagicalImport will try a default lookup before it looks into the userInfo configuration based on the relationship definition from the model file. Every relationship in Core Data has two entities, the source and target. So, MagicalRecord will lookup the target entity, add ‘ID’ to the end of the name, and if there is an attribute with that name, that is how related data will be connected on import. For example, if there is a relationship connected to a Person entity, MagicalImport will look for an attribute named personID.
To specify a different attribute to MagicalImport, specify a value for the relatedByAttribute key in the userInfo structure. When specifying the value of this attribute, it’s important to ensure that you enter in the name of the attribute as it is known to Core Data. This way, if there is a mapping, or fail over list needed in order to determine the lookup value, MagicalImport can grab the proper configuration information straight from the attribute’s userInfo dictionary.
Related By a List of Data IDs
Sometimes you will get a list of data that looks something like this:
{
"name": "Title of Blog post",
"attachments": [3, 5, 100]
}
This type if data is most commonly found in JSON from rails apps. It’s great because it’s efficient for transmission. However, it can be tricky in your code to do the proper lookups and connect the related entities together. MagicalImport supports this type of data format, and is handled automatically when you satisfy the two following conditions:
- The relationship is either a one to many, or many to many relationship
- The relatedByAttribute key is specified with a proper value
These two conditions basically mean its automatically detected.
Failover Keys
It is a common occurrence when grabbing data from web-based JSON APIs that multiple endpoints will return common data structures. However, in some cases, the same data structure may have a slightly different name in the secondary endpoint versus the primary API endpoint. To help with this case, MagicalImport provides a simple method to try multiple keys for a particular attribute or relationship. Keys are tried in a priority order, starting with a priority of one, and continuing until 10 attempts have been made. The assumption was that after 10 tries, and there is still no match, the data is either missing, or you really need to fix your source data.
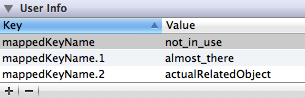
Setting a list of keys to try is as simple as adding ‘mappedKeyName.1‘ with the highest priority value in the userInfo structure. The next key MagicalImport will try will be ‘mappedKeyName.2‘, and so on until it reaches ‘mappedKeyName.9‘. Remember that the fail over order starts with 1, and increments up. This is important to remember if you find that your data isn’t importing even when you specify your list of available keys.
Date Format Parsing
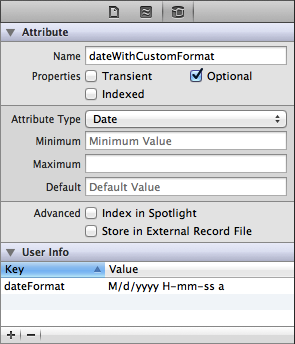 When an attribute on an entity is specified as a Date format, MagicalRecord uses its default date parsing function to read the dates and import them. There are two options when it comes to importing dates, the default, and custom date formats.
When an attribute on an entity is specified as a Date format, MagicalRecord uses its default date parsing function to read the dates and import them. There are two options when it comes to importing dates, the default, and custom date formats.
Default Date Format
The default date format for converting string dates into NSDate objects for use with your entities is:
yyyy-MM-dd’T’HH:mm:ss’Z’
This format was chosen as the default based on the most commonly encountered format when transmitting dates via JSON files. MagicalImport uses two pieces of information to determine when you need to parse dates. Basically, when the attribute is a Date attribute type, MagicalImport assumes that the data will be a string to be parsed, and run if through it’s own NSDateFormatter instance that will read the date string and convert it to an NSDate for use by Core Date and your app.
Custom Date Formats
Of course, there will be times when you encounter date formats that don’t conform to the default date format provided by MagicalRecord. You can, however, specify your own custom date format for use when MagicalRecord converts a date string to an NSDate for any particular attribute. In the userInfo dictionary, specify the key dateFormat, with the value being the date format that matches your data. MagicalRecord will proceed as usually, except it will now use your specified date format to convert the date.
Import Processing Callbacks
Importing data can be tricky depending on any number of factors including the complexity of the data involved or how well the data model matches the data to be imported. MagicalRecord allows for custom handling of individual attribute and relationship importing, as well as giving you control to skip over entire sections of data that may be invalid for importing in the first place.
willImport: and didImport:
If you’ve read Apple’s documentation on Importing data into Core Data, you’ll notice that there’s a mention of creating all your new entities first so that you don’t have to do a fetch request every time you need to relate two objects together during the import processing. MagicalImport has willImport: and didImport: callbacks in your entity objects to allow you to warm up your cache if necessary. It also provides a post import hook for any post processing or notifications the should be fired after an import is complete.
shouldImport:
In some cases, data for importing will not be valid, and should not be imported even though it’s included in your set of data for import. MagicalImport provides a simple way to check data before it’s imported. The goal here was to provide a simple hook for a quick check of a simple attribute value. The return value of this method matters, so to allow MagicalImport to import the data provided as the parameter, return YES. And to skip the entire set of data, return NO. If you don’t specify this method at all on your entity, MagicalImport will just assume you want the data and continue with the import process.
shouldImport<;relationshipName>;:
Sometimes, you’re data for importing is good, except for a small subset of data connected via a relationship. Rather than going through and wasting precious cycles importing the data, only to toss it later when you determine it’s not useful, MagicalRecord provides a nice callback basically asking permission to import a relationship. At this point, you can reach down into the data, perform your check, and return YES if you should import that set of data, or NO if you don’t want that data to be imported. If no shouldImport<;relationshipName>;: instance method is defined on your entity, MagicalRecord will assume you want all that data below. That makes this a deviation on the standard importing logic, when you need it.
- (BOOL) shouldImportContacts:(id)data;
{
NSString *zipCode = [[data lastObject] valueForKey:@"zipCode"];
return IsFormattedAsZipPlusFour(zipCode);
}
In this example, we’re checking the last object in our list for a zip code with the zip+4 format. When it’s not valid, we’ll assume the whole lump of data should be skipped. This code snippet is provided as an example of how to author a shouldImport<;relationshipName>;: method.
import<;attributeName>;: and import<;relationshipName>;:
MagicalImport does not make any assumptions as to the format of your data. While data is being imported, MagicalImport will check the attribute types, and try to make a few choices and to what, if any, data conversions to make. In the case of dates, MagicalRecord knows what to do, but what happens when you encounter a string that is in a structured, but non-standard format that should be converted to a number? The way to handle these special cases with MagicalImport is to implement an instance method named import<;attributeName>;: in your entity.
Sometimes processing data requires more custom knowledge of the data than MagicalRecord should know about. MagicalRecord provides these callbacks to allow you to handle importing of tricky sets of data. Simply implement these methods for any attribute or relationship you wish to have more control over data processing.
- (BOOL) importKeywords:(id)data;
{
NSCharacterSet *set = [NSCharacterSet characterSetWithCharactersInString:@" ,"];
self.keywords = [data componentsSeparatedByCharactersInSet:set];
return YES;
}
In this sample import method, you can see that our entity has an attribute called keywords. In this case, it’s a transient entity, and also an array (configured for us using mogenerator and the Transformable attribute type). Our custom processing callback passed in the data relevant to this attribute as a parameter. This is enough narrowly scoped information for custom processing the data in this short method.
You’ll also notice that this method returns a boolean. This tells MagicalImport that your custom code handled the import. Return a YES if your code processed the data, so that MagicalRecord won’t. This is also the way to skip importing a particular entity, though this behavior is not encouraged. And, conversely, return NO if you want MagicalImport to continue processing the attribute and use the default import routines.
An Example
Let’s try a quick code example using MagicalImport to grab data into your app. Let’s suppose you want to build an RSS Feed reader. You can grab an excellent feed parsing library on github. Generally, the Feed Parser will go through the RSS or Atom styled XML and give you a structure in memory for you to traverse and display. What you may want to do is import this RSS feed into Core Data so you can quickly display it later, search or filter your feeds. Exactly what Core Data is good at doing. Let’s take a look a the code required to import such a feed.
// In APPFeed.m Core Data Entity file
+ (id) feedWithName:(NSString *)name inContext:(NSManagedObjectContext *)context;
{
APPFeed *feed = [self MR_findFirstByAttribute:@"name" withValue:name inContext:context];
if (feed == nil)
{
feed = [self MR_createInContext:context];
feed.name = name;
}
return feed;
}
+ (id) importFeedStream:(NSInputStream *)inputStream;
{
NSError *error = nil;
FPFeed *feed = [FPParser parsedFeedWithStream:inputStream error:&error];
if (feed == nil)
{
NSLog(@"Error Parsing Feed: %@", error);
}
__block APPFeed *appFeed = nil;
[MagicalRecord saveDataWithBlock:^(NSManagedObjectContext *localContext) {
NSString *feedTitle = [feed title];
appFeed = [APPFeed feedWithName:feedTitle inContext:localContext];
[appFeed MR_importValuesForKeysWithObject:feed];
}];
}

The feedWithName:inContext: method is a general purpose pattern I like to implement in my Core Data entities. This let’s me implement how I want to look up an entity, or create it if it is not present in the data store. In this case, the important method is importFeedStream:. The logic is fairly simple. First, we parse the RSS or Atom feed based on an NSInputStream. The result is an FPFeed instance that contains the structure of the feed, sort of like a DOM in HTML. Next, we want to take the object containing the data, the feed object, and send it to the MR_importValuesForKeysWithObject: method. But first, we make sure that we have the correct instance to import into. That is, if there already is an APPFeed object that represents the content of Hacker News, for example, then we want to reuse that object. Otherwise, we need to create it, and that new instance will be our representation for Hacker News. And that’s really all there is to it from the code perspective.
Take a look at the sample Core Data model shown. This model contains a simple set of entities into which this data is to be imported. We can see that we have an APPFeed that contains many APPItems. Each of these also has many attributes which are copied over. In this case, the Core Data model matches the structure of the FPFeed object fairly well, so there isn’t too much custom logic needed. To import the data, we tell MagicalImport that we’ll start at the top, namely with both the entity and the data that correspond to a “Feed”. Then, MagicalImport will begin by copying data from the feed data to the feed entity. For every attribute, it examines the userInfo dictionary for one or more of the features described above, and imports according to those rules. Once the traversal reaches a relationship, in this case items, MagicalImport will examine the relationship, and determine if there is data corresponding to the relationship, and begin importing those entities, and the those item entities to the feed entity while also importing the attribute data according to the rules specified in the userInfo dictionary. Shown in the screenshot here is how we tell MagicalImport that the dateReleased in our model actually matches pubDate in the RSS Feed. With MagicalImport, these mappings are all specified on the specific attributes to which they apply. But in all cases, there is no code needed in order to simply tell MagicalImport which attributes map to which data field.
Testing
While there is no need to touch code beyond the single line required to kick off the import process, in order to verify that your mappings work, I highly encourage you to unit test your data mappings with sample data files. Unit testing with Core Data is fairly straight forward as unit tests go, especially with MagicalRecord at your side. However, downloading the same data over and over can be cumbersome when you have quite a bit of configuration to go through. It’s also easier if you understand how to decouple your data download code from your data import code. You should at least use a small set of unit tests using canned data samples to make sure you’re importing data the way you intend.
Performance
MagicalRecord was designed and implemented without regard specifically to performance. That is, there may currently be spots where performance lags. That does not mean that MagicalRecord is slow. It’s been quite speedy in my informal testing and general use. However, as this is an importing library, there are several logic points that are made. Remember, MagicalImport has to make several determinations about your data as it pertains to the model such as checking if selectors are implemented, determining if relationships are one-to-one, one-to-many, or many-to-many and so forth. The callbacks and traversal logic make your code easier to follow via the callbacks, but over all this will always be slower than if you had just sucked in all the data directly with hand-coded Objective C mappings.
If you do use MagicalRecord to import your data, and it does feel slow, please open a ticket. Or better yet, I invite you to try and fix the performance issue, and send in a pull request. I promise, I won’t bite. It would also really help if you added a test that included your own sample data and your solution to the included suite of unit tests. This will help ensure that that the bug won’t appear again any time soon.
Conclusion
Importing data has always felt like a solvable problem to me since I’ve written quite a bit of data import code for various iOS apps. MagicalImport is my attempt to solve the most common issues I’ve encountered when writing data import code, and make it so that any code I write for data import is specific to the problem at hand, rather than writing more boilerplate code. This also allows for future performance optimizations to benefit all of us with the same class of problems.
It is less common practice in announcement type blog posts to include things that a library doesn’t do, but I’ll list a few things on the todo list. First, MagicalImport doesn’t handle stream parsing. That is, having a structure in memory is required at the moment. This is akin to a DOM XML parser where the entire XML structure is in memory. I’d like to someday have the SAX style option of stream parsing and importing based on events.
The fact that parsing relies on an in-memory data structure, that also means that a particularly large set of data could mean a rather large memory footprint during import. The most straight forward way to mitigate this is to measure any memory overhead during your imports, and break them up as necessary to keep your live memory footprint under control. But if there are other ways this could be improved, I’d love to hear your ideas.
An interesting side benefit of having the import<;attributeName>;: and import<;relationshipName>;: callback hooks is that my import code is far more simple, quicker to browse through. The specific code to process a particular attribute or relationship is in it’s own method making the logic of parsing a particular piece of data and easier to test and debug.
Also, one of my favorite aspects of MagicalImport is that there is very little code involved in the simplest of imports. Placing the mapping configuration in the Model files may feel a little cumbersome at first, and when things are not working, it can be a little tricky to find the mis-configured attribute. However, placing key-value configuration close to the data it configures feels like a good compromise of configuration and automation.
I hope you find MagicalImport as useful in your code and apps as I’ve found it in mine. I look forward to seeing MagicalImport in your apps! And if you do add it, I’d love to see your app on the list of apps with MagicalRecord!