Fetched Properties; useful?
Core Data has a number of features and abilities that are not commonly used. Chief among those are fetched properties. In discussing them with a number of developers, most have never heard of them and those who have heard of them couldn’t come up with a viable use case for them.
To be honest, I don’t have a lot of use cases for them myself. They are definitely not one of the core features of Core Data that I recommend people learning when they are initially getting comfortable with the framework.
In this article we will discuss one use case for fetched properties and the impacts.
## The Use Case
The use case for fetched properties that I have run across a few times comes into play when you have more than one persistent store file on disk. Imagine you are building a recipe application (one of my favorite examples). You decide to include a pre-built read-only database with existing recipes. However, your application has the ability to add notes and social comments to a recipe.
You want to keep the recipe database as read only (you have a separate one for new recipes) but you want the user to be able to add comments. Where do we put the data?
In this contrived situation, storing the comments (and other metadata) in another store makes sense. Unfortunately we can’t have relationships across physically separate stores.
Enter the Fetched Property.
## Fetched Property
A fetched property is a property added to a `NSManagedObject` entity that instead of storing a value or a relationship, it stores a `NSFetchRequest`. When the property is accessed for the first time the `NSFetchRequest` is fired and the results are returned.
A fetched property always returns a `NSArray` (well a subclass but that is a minor detail) and it can be configured to sort the results.
Unfortunately, the editor in Xcode does not permit adding sort criteria so the only way to add a sort to a fetched property is to create the fetched property in code. Hopefully that will be corrected in some future release of Xcode.
What does a fetched property look like? In the Core Data model editor, a fetched property is added just like an attribute or a relationship. Then in the Data Model inspector you can configure the `NSFetchRequest`.
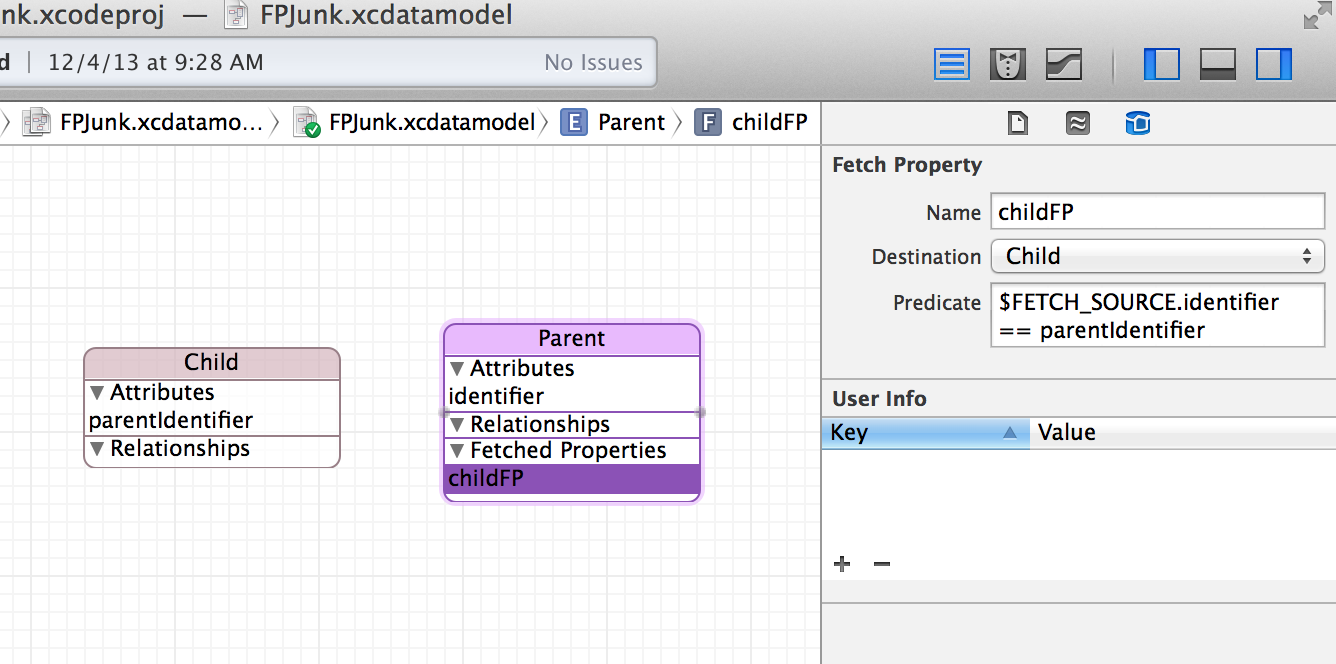
A Fetched Property shown in Xcode’s data modeler
The Destination is the entity that will be returned by the fetched property. The predicate is a string representation of the `NSPredicate` configured within the `NSFetchRequest`.
Further, the predicate can use one of two variables to help configure it:
`$FETCH_SOURCE` gets replaced by a reference to the entity that owns the fetched property. By using this variable we can reference properties in the owning entity.
`$FETCHED_PROPERTY` gets replaced by a reference to the the property description of the fetched property. The property description includes key value pairs that are accessible from within the predicate. I have not run across a situation where I have used this variable.
## The sharp edges
There are unfortunately some concerns with fetched properties.
Unlike a relationship, there is no way to pre-fetch a fetched property. Therefore, if you are going to fetch a large number of entities and then desire to access the fetched property for those properties, they are going to be fetched individually. This will drastically impact performance.
Fetched Properties are only fetched once per context without a reset. This means that if you add other objects that would qualify for the fetched property after the property has been fetched then they won’t be included if you call the fetched property again. To *reset* the fetched property requires a call to `-refreshObject:mergeChanges:`.
A fetched property always returns an array. While this is not a major issue if in fact you want more than one object returned. However, when that is not the case it is an additional method call that you need to make every time or add a convenience method. More code equals more bugs.
## To use or not to use
Fetched properties are not a main line piece of Core Data. It appears that even the Core Data team (or the Xcode team at least) agrees with that assessment based on how little effort is given to them in the model editor. Should you use them?
It depends. If you are joining two separate persistent stores and need a *soft* relationship between entities in those stores then yes, you can use them. They do work.
Be mindful of the edges, they are sharp.
Automating OS X app test build distribution across multiple OS versions
With Apple now shipping OS X upgrades every 12-15 months, Mac developers are very quickly finding themselves supporting their apps on multiple OS X versions. Until recently, my approach to testing on multiple OS X versions involved partitioning an external USB drive and installing the OS X versions onto it and booting off the partitions to test.
While this approach is inexpensive, the test-discover-reboot-fix-build-test cycle just got to be too much for even this frugal Scot.
Enter the Mac mini
My new solution has 2 parts: a maxed out Mac mini with VMware Fusion to support all the targeted OS X versions and a scripted piece that will sync new test builds to the VMs.
The current $799 Mac mini has a quad-core Intel Core i7, a 1TB HD and is expandable to 16GB of RAM. Our local MicroCenter had a $749 sale on that model so I picked one up along with a 16GB RAM upgrade. After I setup 4 VMs, one for each of 10.6 – 10.9, I found the performance to be incredibly slow. Analyzing the issue quickly identified the speed of the stock HD as a bottleneck, so after considering returning the whole kit for a BTO Fusion Drive model, I picked up an OWC 240GB Mercury EXTREME™ Pro 6G SSD, and now the performance is great. (Installing an extra HD in a Mac mini is possible, but if you do, make sure you watch and understand the videos on the topic and make sure you order the correct parts to install in your Mac mini.)
Moving the builds around
Each of my Mac Xcode projects now has an extra scheme called MyApp test build. The following scheme settings are used: In Run MyApp.app, I’m using the Release build configuration and I’ve set Launch to Wait for MyApp.app to launch since I don’t intend to run these builds from Xcode. Most importantly, in Build->Post Actions, I’ve added a Run Script Action with Provide build settings from set to the app. The script below creates a new uniquely-named folder in the $root_destination_folder every time you build and will copy the resulting product into that newly created folder. The folder name combines date/time, product name, and the current git describe. The $root_destination_folder should be in a folder that is synced by a service. I used Dropbox at first, but it doesn’t seem optimized for the large number of small files that compose a Mac application bundle, even with LAN syncing turned on. I’m now using BitTorrent Sync, which uses the BitTorrent protocol. Even as a beta release, I had great success with it. By adding the shared folder to the BitTorrent Sync client on each test VM, every time I make a test build, it automatically appears on each VM.
By running multiple OS X versions in VMs simultaneously and syncing test builds, I’ve nearly eliminated all the waiting involved in testing and iterating across multiple OS X versions.
root_destination_folder=/Users/fraser/Development/test_builds_sync
date=`date +%Y%m%d-%H%M%S`
product=$PRODUCT_NAME
git=/usr/bin/git
cd $SRCROOT
version=`$git describe --dirty`
full_dir_path=$root_destination_folder/$date-$product-$version
mkdir -p $full_dir_path
cp -RH $TARGET_BUILD_DIR/$FULL_PRODUCT_NAME $full_dir_path
Note 1: For testing on Mac OS X 10.6 Snow Leopard, only Snow Leopard Server is supported in VMware Fusion. Apple has made Snow Leopard Server available to paid Mac developers as a free download. The provided serial number expires at the end of 2014.
Using GIT In Xcode
Git has become a very popular version control system in iOS and Mac development. Git comes with a set of command line tools to check status, commit changes, view logs, make and merge branches, and coordinate commits with a remote repository. There are a number of desktop apps that can perform these functions, including Xcode. When I ask other iOS and Mac developers how they interact with Git, most say they use the command line or a separate desktop app like Tower. I find very few developers use Xcode for even some basic Git tasks, and many developers are not aware of the Git support Xcode offers.
For my own workflow, I like to minimize the number of tools used and number of switches between apps needed to complete a task. So, I decided to attempt to use Xcode exclusively to interact with Git and share my results. So far I have been pleasantly surprised at what all Xcode can do with Git. If you have not taken a look at Xcode’s support for Git, you may be surprised how much you can accomplish.
This article assumes basic familiarity with Xcode and Git, and describes Git functionality present in Xcode version 4.6.2. (more…)
Creating A Happy Appy Song
App developers need ways to promote their apps and audio and video provide a way to do that. At a recent iOS developer camp in Colorado I gave a talk in which I demonstrated some ways developers can create their own creative content like audio and video in-house. In one segment I demonstrated a technique that I refer to as creating a Happy Appy Song. What is it, you ask. You’ve heard it. It’s a happy sounding fanciful tune that plays in the background as some narrator describes the wonders and benefits of an app (or other product for that matter). The basic premise of the happy appy song is that, first of all, it’s easy to create, but second there’s a simple formula. Here is all you need:
1. A happy chord progression in a major key
2. A simple drumbeat
3. A glockenspiel sound
And now I present to you, Creating a Happy Appy Song
[ylwm_vimeo height=”400″ width=”600″]66576979[/ylwm_vimeo]
iOS Crash Logs On iCloud Synced Devices
I tweeted a call for help today to figure out how to get crash logs from a device that syncs with iCloud rather than with iTunes and a cable. The issue is that you can only sync with one and not both and switching between them willy nilly can be perilous unless you enjoy losing your data just for the fun of it.
Several responses suggested taking things into my own hands by rolling my own logging mechanism when building an app I intend to ship. I think this is likely the approach I will take in the future, however, it doesn’t help my immediate problem. How do I get crash logs from an app I already shipped that is running on client’s device not physically located near me? Here’s a summary of what people suggested. Drill down in the settings app and copy the contents of the crash log like this (click/tap to enlarge):
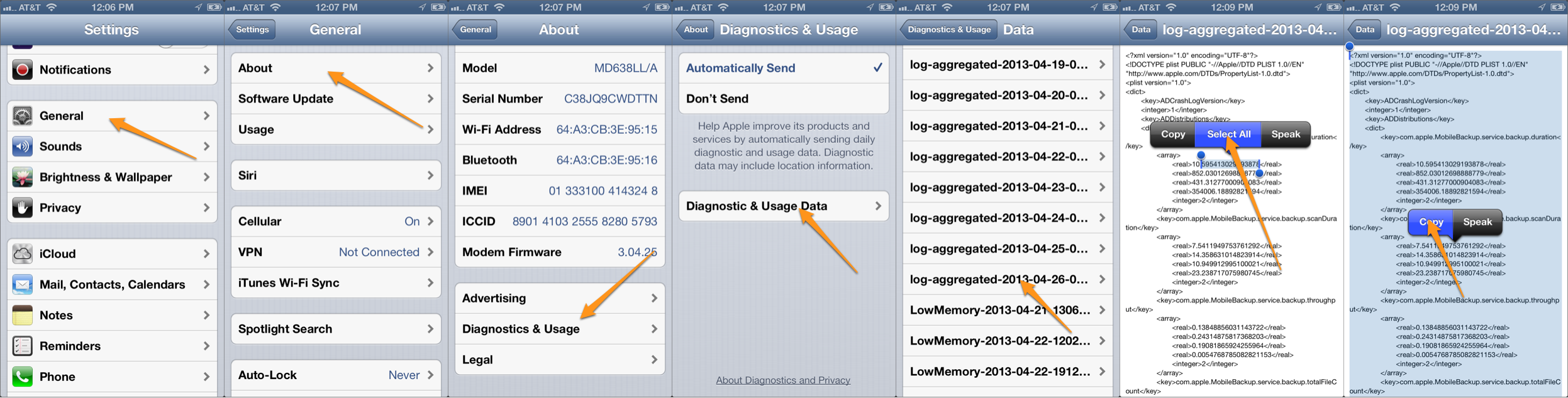
Then, paste that into an email:
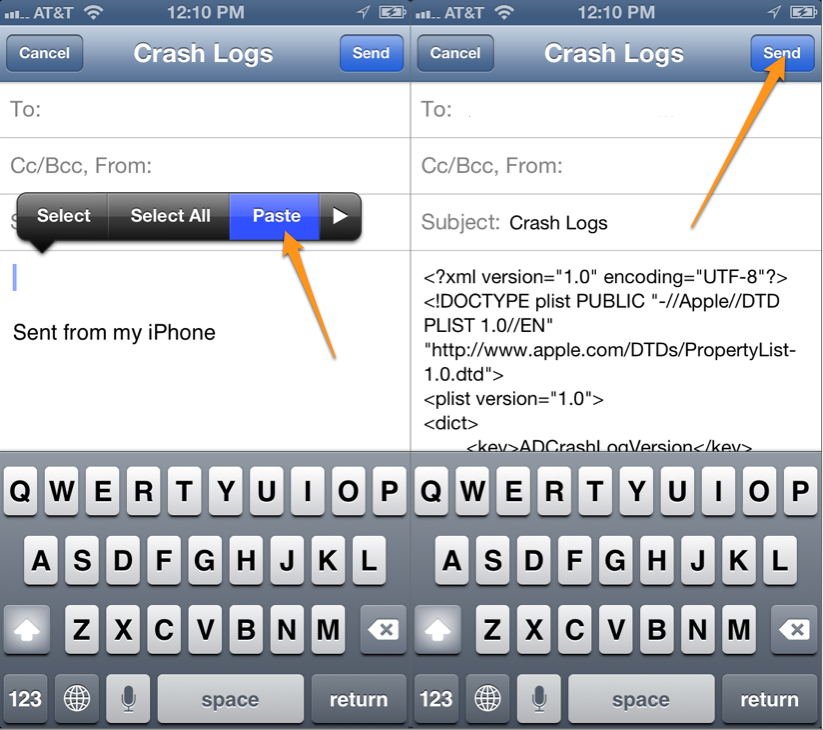
Then you can send the crash log to any email address you specify.
It certainly is not a pretty approach, but it will get the job done.
Thanks to the folks who responded to my call for help, @davidiom, @therealkerni, @thenighttrader, and @rckoenes. I appreciate it!
StackOverflow Reputation As A Hiring Metric
I’ve been using StackOverflow nearly since it started back in 2008. I remember when it first started there didn’t seem to be much going on and so I forgot about it for a time. Then, one day, while searching the interwebs for an answer to a programming question, SO was the first hit in my search results. At that point I went back and started using it regularly–not only to find answers, but to offer my own experiences and expertise to help others. It’s a great site and I have nothing but high praise for its founders, Jeff Atwood and Joel Spolsky. The entire StackExchange network is an impressive engineering achievement. (more…)
Anonymous Image File Upload in iOS With Imgur
It seems like a pretty useful feature, anonymous image file upload in iOS with imgur. If you need to upload images and don’t want to fool with some authentication mess like OAuth this technique is perfect. There are libraries that have simplified the OAuth process, however, it’s nice to be able to just initiate an upload, get a result URL back and be on your way. No fuss, no muss. That’s what I was looking for, so I wrote a little app that demonstrates how to do exactly that.
(more…)
Querying Objective-C Data Collections
In my Xcode LLDB Tutorial, I mention using the debugger to interrogate data collections. Well, I wanted to elaborate on that idea a little because there are some techniques you can use for querying objective-c data collections that are very powerful.
If you develop apps for clients, you my be one of the lucky ones–the ones who actually get to model your data and use Core Data to store and access it. But I’m betting there are many of you who aren’t the lucky ones–or at least not on all of your projects. From time to time you have to deal with data in whatever format your client gives it to you. Maybe you’ve even suggested taking the CSVs or Plists (or whatever other formats clients have come up with to ruin your life) and actually loading those into Core Data. But they don’t get Core Data and they shoot down the idea. Well, you may want to just walk away from the gig. However, if you’re like me, you’ve got bills to pay and clients (the good ones at least) tend to help you accomplish that. Well, fortunately for us, Objective-C makes dealing with this kind of data manageable using a little technique known as KVC, Key-Value-Coding, with array filtering and sorting.
This is not an advanced topic, so if you’re already familiar with how KVC and array filtering and sorting works, this post may not help you as much. But for those of you who are fairly new to iOS development, you need to know about this magical feature of the language as all the senior iOS developers use it and you should too. (more…)
Down with Magic Strings!
Developing iOS apps in Xcode is pretty great. With Objective-C and llvm we get type checking and autocompletion of all our classes and method names which is a nice improvement over my favorite dynamic languages. Unfortunately there are still some places where the compiler can’t help us. There are various resources we load from files like images, nibs & xibs and other resources which we need to specify by name, like a view controller we want to load from a storyboard.
(more…)
NSFetchedResultsController -sectionNameKeyPath discussion
Core Data and NSFetchedResultsController do clever things under-the-hood to improve performance, such as loading data in batches as it’s needed. But there’s a gotcha with grouping data with sectionNameKeyPath than can cause a big hit in performance. Check this out.
(more…)
Leveraging Basic SEO
Being that I’m a blogger as well as a software developer, I’m going to deviate a little from the normal Cocoa specific programming fare and focus a bit on leveraging basic SEO on your blog. These are some of the lessons I’ve learned and I think they might be helpful to others.
People do some pretty shady things to try to improve their page rank. There are companies who claim to be able to improve page rank. In fact it’s an entire market full of snake oil sales people. I’m sure there are some legitimate “consultants” out there, but they’re tough to find. In the end, the techniques for “optimizing” your page so that search engines find your content more readily are the same for the legit folks, like bloggers such as those of us who write for CIMGF, as they are for the folks who are trying to game the system. The difference is that gaming the system is exactly what true SEO helps eliminate. Google will blacklist your site if they detect you are trying to game them and getting off of that list will prove very difficult. It is not worth it to game the system. In the end when leveraging basic SEO, the old adage remains, “Content is King”. That single principle is the one and only differentiator. Write great content for your users and everything else will fall into place. (more…)
Xcode LLDB Tutorial
What inspired the Xcode LLDB Tutorial? Well, I tweeted this the other day:
A few people then responded over twitter asking that I would elaborate by writing a tutorial here on CIMGF. So here it is. Your wish is my command, The Xcode LLDB Tutorial
A Better Fullscreen Asset Viewer with QuickLook
Since last year I’ve spent a lot of time working on iPad apps for medical device companies. These companies want to be able to display their sales materials/digital assets to potential buyers on the iPad because of its gorgeous presentation. We can’t blame them. This is a great choice especially with the retina display on the third generation iPad. It’s incredibly compelling.
Our go-to solution for presenting these files until recently has been to just load everything into a UIWebView because it supports so many formats. Voila! Done! We like simple solutions to problems that would otherwise be very difficult.
This solution has worked great, but over time it’s become a noticeably dull spot in the app with some UX problems to boot. This is not good–especially for the part of the app that gets the most customer face time. It needs to shine. To go fullscreen, we just load a full size view controller modally. One issue with this approach though was that it only worked in landscape. For some reason it would get wonky (engineering parlance for, “um, I don’t know”) if we allowed both orientations since the rest of the app supported landscape only. It also had a nav bar that would never be hidden, so the user would always see it even when they were scrolling through the document content. Finally, there was no way to jump down deep into a document. If you needed to get to page 325, for example, you had to scroll all the way there. That’s just a bad user experience–incredibly tedious making it unlikely anyone would use it with a large document. These were some significant drawbacks and I didn’t have a good solution to bring the polish that this segment of the app deserved. (more…)
Importing Data Made Easy
Importing data is a problem that feels like it should have a library of work ready for you to use. Especially when it comes to importing data into Core Data where you have a description of your data to work with. What if there was such a library, or reusable framework, of importing code that basically converts raw data to Core Data entities? Well, wonder no further because in this post, I’ll be discussing a new addition to the MagicalRecord toolset, MagicalImport available now on Github!
Unit Testing with Core Data
Whether you subscribe to Test Driven Development (TDD) or another testing practice, when it comes automated unit testing with Core Data, things can be a little tricky. But if you keep it simple, and take things step by step, you can get up and running with unit testing using Core Data fairly quickly. We’ll explore the what, how and why of unit testing with Core Data. We’ll also be using the helper library MagicalRecord. MagicalRecord not only lets us get up and running faster, but helps to cut down on the noise in our tests.